Method
SimCLR v2
- deeper but less wider network:
- 152-layer ResNet with 3× wider channels
- selective kernels (SK) ,channel-wise attention mechanism
- obtain a 29% relative improvement in top-1 accuracy when fine-tuned on 1% of labeled examples
- deep projection (non-linear):
- instead of throwing away g(·) entirely after pretraining as in SimCLR, we fine-tune from a middle layer
- use a 3-layer projection head and fine-tuning from the 1st layer of projection head
- 14% relative improvement in top-1 accuracy when fine-tuned on 1% of labeled examples
- memory mechanism (MoCo):
- designates a memory network (with a moving average of weights for stabilization) whose output will be buffered as negative examples
- yields an improvement of ∼1% for linear evaluation as well as when fine-tuning on 1% of labeled examples
Fine-tuning
- incorporate part of the MLP projection head into the base encoder during the fine-tuning
Self-training / knowledge distillation via unlabeled examples
mean-teacher model:
use the fine-tuned network as a teacher to impute labels for training a student network
loss:

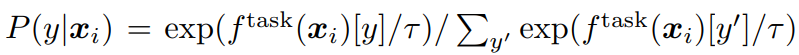
t: scalar temperature parameter, balance the distribution


